LOG — eksperymenty · co · na czym · z jakim wynikiem
zaktualizowano 2026-06-15Log eksperymentów
2026-06-15Stawianie modded-nanogpt na polskim od zera: pięć rzeczy, które się wywaliły (i czemu)CZYSTY
skład danych
eval (held-out)
Bug 1 — kompilacja kernela CUDA
triton_kernels.py miał hardkod cuda_include_dirs=/usr/local/cuda/include (nie istnieje na boxie) → nvrtc nie znajdował cuda_bf16.h. Fix: wskazać include na pakiety pip (nvidia-cuda-runtime-cu12)
Bug 2 — max_num_docs (crash na step 500)
bufor granic dokumentów stuningowany pod FineWeb (długie doki); nasze gęste krótkie wiki-doki przepełniły go (81 doków > 64) → RuntimeError. Fix: dzielnik //48 zamiast //300 + większa tablica
Bug 3 — 51 GB H100 zajęte
Livebook (Erlang/EXLA, root-owned) prealokował 51 z 80 GB; trening dostał 27 GB. Fix: sudo kill beam.smp (XLA agresywnie grabi VRAM nawet idle)
Bug 4 — własny błąd
patch zostawił przecinek za komentarzem (vocab_size=32896 # ...,) → przecinek zakomentowany → SyntaxError. Banał, kosztował relaunch
Bug 5 — thrashing launchy
kilka równoległych biegów walczących o GPU; pgrep-guard złapał zdychający proces i nie odpalił nowego. Fix: czysty kill → JEDEN bieg + persistent compile cache (TORCHINDUCTOR_CACHE_DIR), żeby 7-min warmup nie powtarzał się przy każdym relaunchu
Detal — vocab a potęgi 2
32768 to czysta potęga dwójki (ryzyko gorszej ścieżki cuBLAS, ostrzeżenie Karpathy'ego); model spadowany do 32896 (×128, NIE potęga 2), tokenizer zostaje 32768 — nadmiarowe wiersze to 'useless dimensions', nigdy nie są targetem
Wniosek
cudze speedruny są stuningowane pod ICH dane (FineWeb = długie doki); adaptacja do innego rozkładu długości dokumentów wymaga przejrzenia zaszytych stałych. Plus znów: jeden proces, checkpoint/resume, cache kompilacji — inaczej traci się godziny na crashach i warmupie
2026-06-15Własny polski BPE koduje polski 1.58× gęściej niż Llama-3CZYSTY
skład danych
eval (held-out)
polish-32k (nasz, 32k vocab)
1.738 tok/słowo — 1.00× (baseline)
Llama-3 (128k vocab)
2.744 tok/słowo — 1.58× gorzej
GPT-2 (50k vocab)
3.659 tok/słowo — 2.10× gorzej
Dlaczego ogólne tokenizery słabo
ogólne/multilingual słowniki nigdy nie dostały dedykowanego polskiego; nasz dedykowany BPE bije nawet 4× większy słownik Llamy-3
Konsekwencja
przy tym samym vocab (32k) nasz koduje polski znacznie gęściej → więcej tekstu w oknie kontekstu, efektywniejszy trening na token
Caveat (uczciwie)
próbka in-domain (Wikipedia); wszystkie dostały IDENTYCZNY tekst, a skala 1.58× jest za duża by to był artefakt domeny. Pancerny pomiar OOD do dorobienia
2026-06-15Diagnoza: „przegrana” na CBD/DYK/GSM8K to bug harnessu, nie modeluCZYSTY
skład danych
wykresy
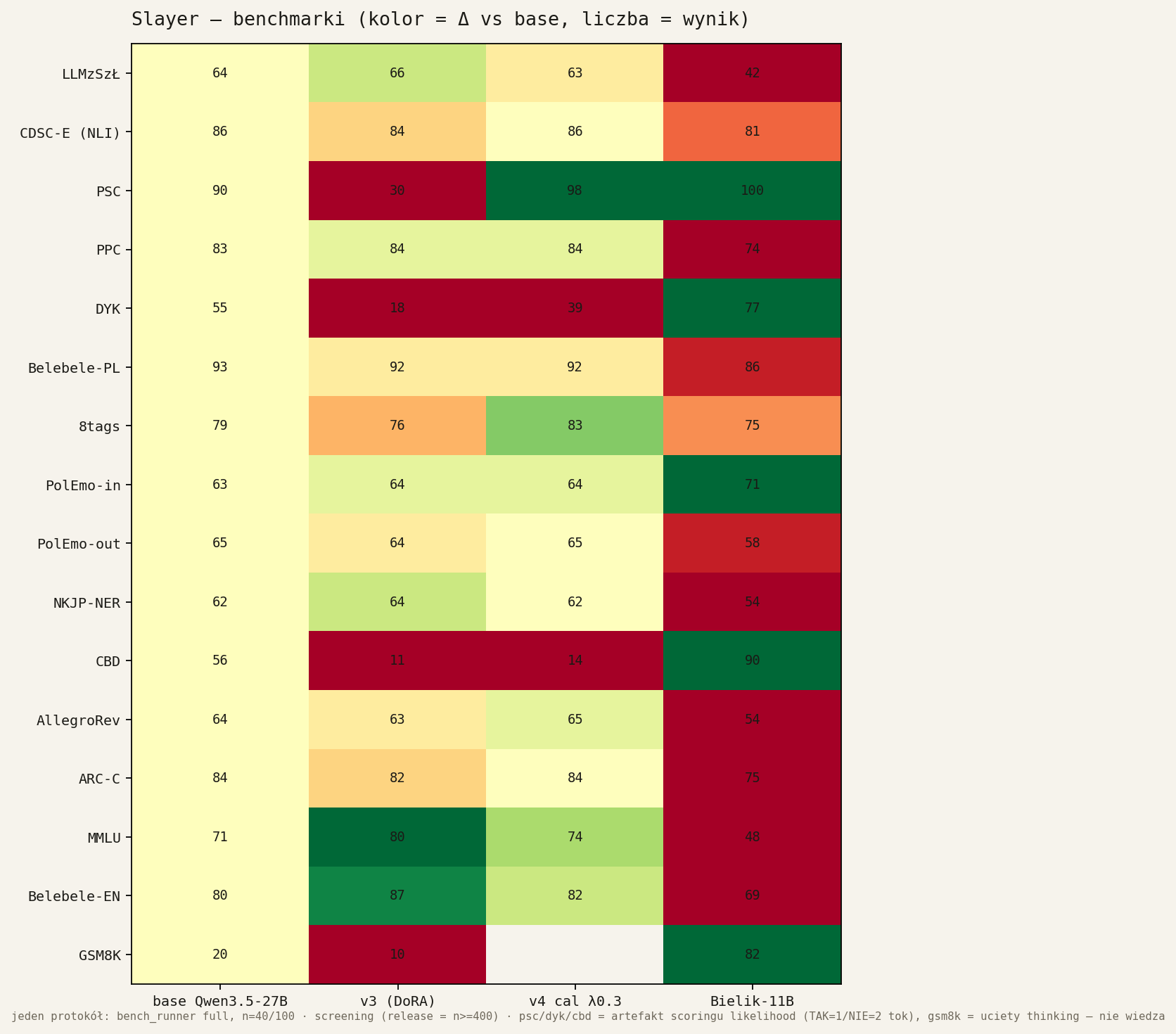
Trwa: re-score DYK/PSC + pełny rerun 4 modeli z poprawnym scoringiem (kalibracja + F1 wg KLEJ) i większym budżetem tokenów GSM8K. Macierz powyżej zostanie podmieniona na wersję po naprawie.
eval (held-out)
Gdzie scoring nas zaniża (n=100)
CBD, DYK, +GSM8K (i PSC)
Z tego realna słabość
tylko PolEmo-in — reszta to artefakty pomiaru
TAK/NIE — długość tokenów (zmierzone)
TAK=1 token, NIE=2 tokeny; Tak/Nie=1/1, YES/NO=1/1 (tylko WIELKIE TAK/NIE są asymetryczne)
CBD base — sum logprob (none)
acc=60 F1=35, predTAK=51/100 (gold TAK=11) — bias ku 1-tokenowemu TAK
CBD base — per-token (mean)
acc=89 F1=15 — POZORNY fix: to baseline większościowy (89% NIE), F1 pada
CBD base — kalibracja kontekstowa + any-lang
acc=75 F1=44 — realny sygnał (predTAK=34)
Ucieczka do angielskiego (YES/NO)
0/100 — model ZAWSZE preferuje polskie TAK/NIE; hipoteza języka obalona
GSM8K base
20 (nierealne dla Qwen 27B) — thinking ucięty przy max_new=512, parser nie dożywa do '####'
Pytanie wyjściowe: „czemu mamy fuckup na CBD/DYK?”. Odpowiedź: to DWA różne bugi harnessu, nie modelu. (1) CBD/DYK/PSC są scorowane LIKELIHOODEM (nie generacją) — porównujemy sumę logprobów ' TAK' vs ' NIE'. Ale ' TAK'=1 token, ' NIE'=2 tokeny, a scorer sumuje (nie uśrednia) → wbudowany bias ku TAK. Gold jest w 82–89% NIE, więc model „przewiduje” TAK 51–64 razy i accuracy się sypie — DOKŁADNIE proporcjonalnie do niezbalansowania (CBD 89%NIE→najgorzej). Przejście na per-token (mean) to PUŁAPKA: zwija się do samego NIE = baseline większościowy (CBD acc=89 ale F1=15). Prawdziwy fix: kalibracja kontekstowa (odjęcie logprobu etykiety na pustym promptcie) + metryka F1 (oficjalna w KLEJ), stosowane JEDNAKOWO do wszystkich modeli (anti-benchmaxxing). Po kalibracji base wraca do sensownego F1=44. (2) Hipoteza „model woli angielskie YES/NO” obalona twardo: EN-leak=0/100 — przy scoringu likelihood model zawsze stawia na polskie TAK/NIE. (3) GSM8K to osobny bug — generacja z uciętym thinkingiem (max_new=512), base=20 jest nierealne; fix = większy budżet tokenów + format-aware extraction. Wniosek: z 5 „przegranych” realna jest tylko PolEmo-in; reszta to harness. Reguła: każda poprawka pomiaru idzie na wszystkie modele naraz, nigdy per-model.
2026-06-14V4 Faza 0 — pomiar (likelihood) + kalibracja λ (cal-l030)CZYSTY
skład danych
wykresy
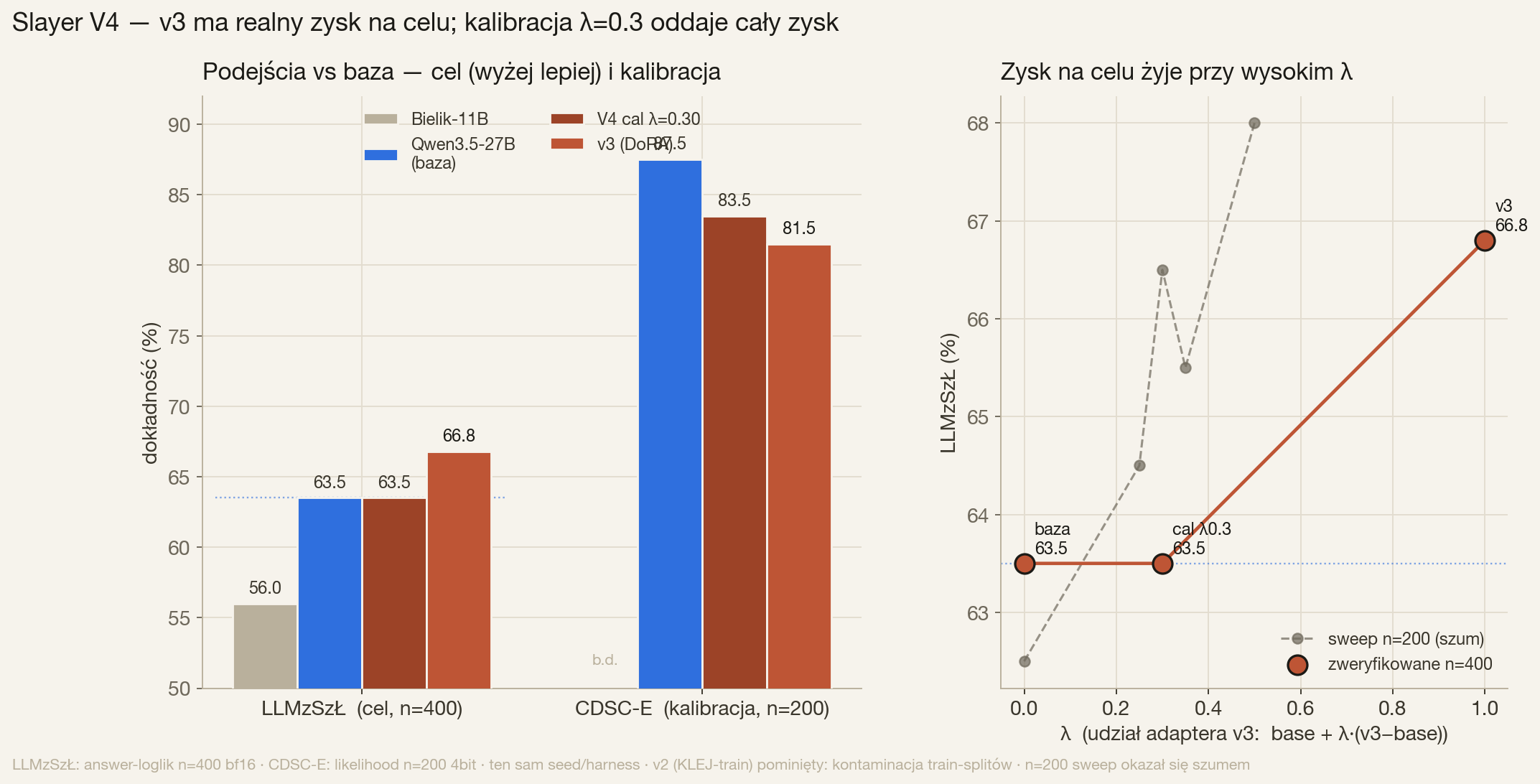
Trwa pełny screen base vs v3 vs cal-l030: KLEJ ×12 (likelihood) + LLMzSzŁ + EN-retention (ARC-C, MMLU, Belebele-EN, GSM8K). Runner bierze model z HF/katalogu, sampling n=100, zapis przyrostowy + watchdog.
eval (held-out)
LLMzSzŁ (n=400): base / v3 / cal-l030
63.5 / 66.8 / 63.5
CDSC-E likelihood (n=200): base / v3 / cal-l030
87.5 / 81.5 / 83.5
CDSC-E v3: generacja vs likelihood
64.5 → 81.5 (czyli −22.5 → −6.0)
Faza 0 V4 to diagnoza i kalibracja, nie nowy trening. (1) „Katastrofa” CDSC-E v3 była w ~3/4 artefaktem POMIARU: generacja+parser dawały 64.5, ale likelihood (scoring etykiet) daje 81.5 — realny spadek to −6.0, nie −22.5. Wniosek operacyjny: zadania klasyfikacyjne mierzymy likelihood. (2) v3 to realny zysk na celu (LLMzSzŁ +3.3) bez szerokiej regresji KLEJ — makro płaskie, sentyment +9/+7.5. (3) Próba naprawy przez merge wag λ=0.30 (cal-l030) wyglądała świetnie na n=200 (CDSC 82 / LLMzSzŁ 66.5), ale twardy rerun n=400 pokazał, że oddała CAŁY zysk celu (LLMzSzŁ 63.5 = baza), zostawiając −4 na CDSC. Mała próbka skłamała. Wniosek: decyzje o release wyłącznie na n≥400; przy niskim λ koszt CDSC rośnie szybciej niż zysk LLMzSzŁ, więc post-hoc merge nie da gate-clean wygranej — prawdziwy fix to trening anti-collapse (q/v only, niższy lr, hard-neutral NLI + KL-to-base). Reguła V4: zero benchmark train splitów jako paliwa, też KLEJ.
2026-06-13slayer-v3 — trening + pierwszy wynik LLMzSzŁCZYSTY
skład danych
destylacja zdolności 1453EN retencja 484human PL (Aya/OASST) 175styl 121
hiperparametry
LR: 5e-5 cosineepoki: 2kroki: 246MAX_LEN: 2048batch_eff: 16DoRA: r16/α32early-stop: 12% holdout / patience 2
krzywa loss

eval-loss spadał monotonicznie do 0.441 (brak overfittingu, early-stop nie odpalił); ~36 s/krok na H100 80GB, 2h23m
eval (held-out)
v3 — LLMzSzŁ acc
66.8
baza Qwen3.5-27B (ten box)
63.5
slayer v1
65.0
Pierwszy czysty wynik v3 (SFT stylu na Qwen3.5-27B, decon gate CZYSTY). Wewnetrzna bramka LLMzSzL likelihood (n=400): v3 +3.3 nad baza (CI sie naklada, odporne). Vibe-check (6 promptow): v3 pisze naturalniejsza polszczyzna bez markdown/korpo-tonu na tekstach codziennych, traci gestosc/forme na kreatywnych (wiersz, gwara). Wiedza bez regresji. To wewnetrzny gate, nie oficjalne twierdzenie 5-shot. CPT (EntiGraph) odlozone — Munin (Danish FM) potwierdzil, ze SFT-first na Qwen-base wystarcza.
2026-06-11weryfikacja zewn. destylacji 10k (model PL 11B)CZYSTY
skład danych
surowe 10304po kuracji 9769verified (fakty ok) 4091
eval (held-out)
powazne błędy
4940
fakty ok
4094
drobne
732
51% surowej destylacji z 11B na pytaniach o długi ogon to konfabulacje (zmyślone daty OSP, nieistniejące idiomy). Do miksu v3 weszła wyłącznie frakcja verified (374 ex). Wniosek: zewnętrzne SFT wiedzy bez weryfikatora per item truje model.
2026-06-11EntiGraph — korpusy wiedzy 2×10M tok (wiki PL-focus + ZPE)CZYSTY
skład danych
wiki: relation 46713wiki: para/sum/qa 45489zpe: relation 45097zpe: para/sum/qa 47803
slayer-data/knowledge/entigraph_pl_focus.clean.jsonl (shardy w repo datasets)
~200k faktów: 6.5k artykułów o Polsce + 64k akapitów egzaminacyjnych ZPE. Audyt verbatim na ZPE wyciął 1274 kolizje (1.37%; materiał szkolny pokrywa się z frazami egzaminów z evali — dokładnie po to jest bramka). Inżynieria throughput: 430 -> 13 000 tok/s (30x). Koszt łączny ~$8.
2026-06-11graf encji — wiedza kompozycyjna (pilot 2-hop)CZYSTY
skład danych
bridge 992hop_qa 971
bench/entigraph_hops.py
Pilot złapał pułapkę grafu: 53% ścieżek szło przez węzły-daty (absurdy typu piłkarz↔ceny gazu przez wspólną datę). Fix: daty poza grafem + odcięcie hubów po in-degree. Po fixie ścieżki sensowne (Szkotowo→Jan Kostka→pochówek w Lisewie).
2026-06-11train_v3 — czysty miks SFTCZYSTY
skład danych
distill własny 1022ext_distill_verified 374human_pl 344EN retencja 499
trening jeszcze nie wystartował — najpierw pilot CPT + probe
Zero train/test splitów benchmarków. Audyt wykrył i usunął wyciek 85 promptów holdoutu stylu (obecny w miksie v2; v1 czysty: 0 wspólnych). Szczegóły miksu: /v3.
2026-06-11knowledge_probe_v1 — długi ogon wiedzy o Polsce (smoke)CZYSTY
skład danych
polonica 38ogolne 33
eval (held-out)
Qwen9B polonica
18.4
Qwen27B polonica
15.8
Qwen9B ogólne
30.3
Qwen27B ogólne
33.3
Długi ogon (regionalia, lokalne fakty) leży u wszystkich: 16-29%. Baza 27B najsłabsza na polonica przy dobrej wiedzy ogólnej. Wniosek: CPT na zmultiplikowanym syntetycznie ogonie (EntiGraph 10M) ma duże przestrzenie do odzyskania; cel po CPT: znaczący wzrost na polonica. n=71 to smoke: różnice na polonica (n=38) jeszcze nieistotne statystycznie; potwierdzenie na probe 300-500 + drugi niezależny sędzia. Itemy probe = held-out (exclusion list z treningu CPT).
2026-06-09slayer-v2-klejKONTAMINACJA
87.83 macro · base 81.83 (Δ 6.0)
skład danych
styl 1004KLEJ train 1100KLEJ synth 150replay 228
dataset
🤗 kacperwikiel/slayer-data-v2-klej-mix ↗
Miks 2482 przykładów: 1004 styl (teacher rewrite) + 1100 KLEJ train-split (KONTAMINACJA) + 150 synth KLEJ + 228 replay (anti-forgetting). Pełne pliki + skład co do przykładu na HF (prywatny).
hiperparametry
DoRA r: 16alpha: 32LR: 5e-5epochs: 2batch: 4×8max_len: 1024quant: bf16early_stop: patience 2
krzywa loss
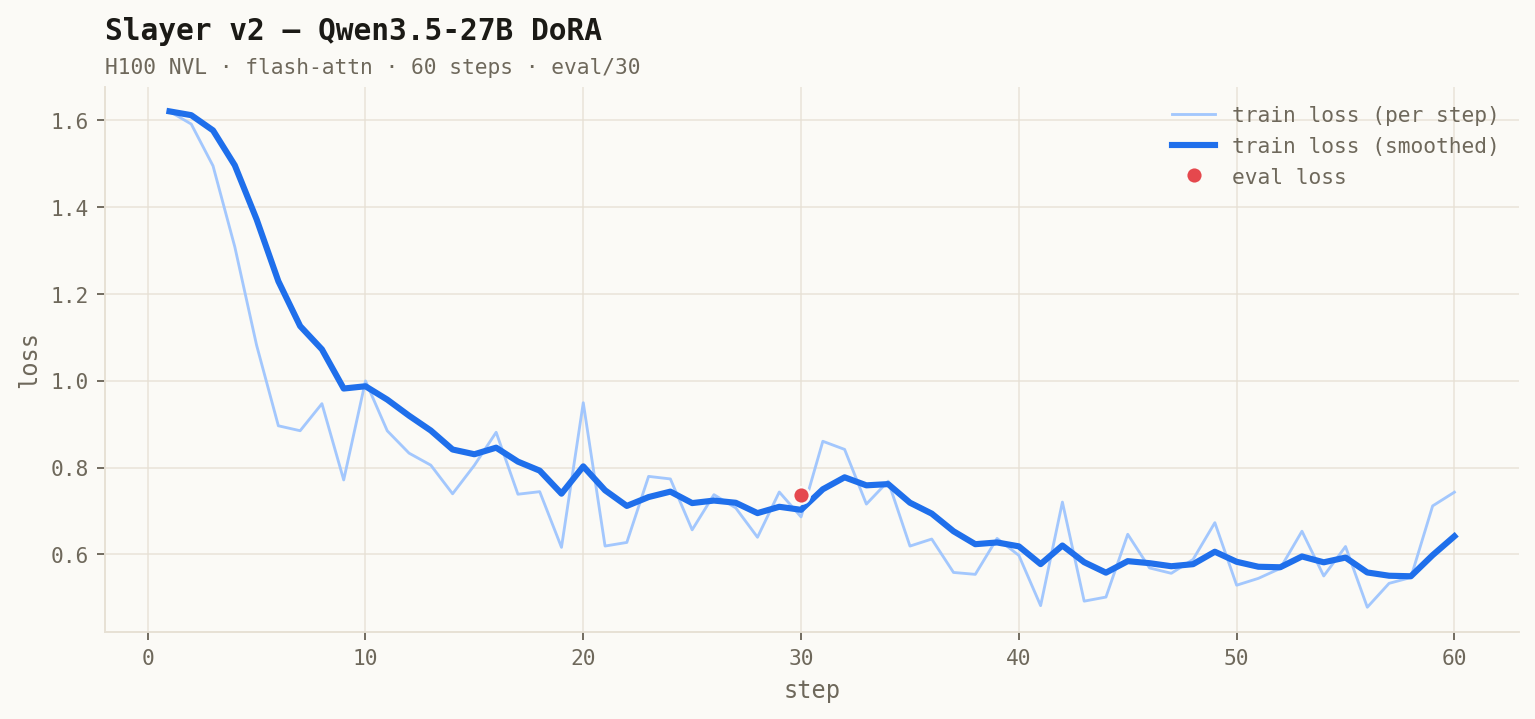
⏹ step 150 — best eval-loss 0.6978 (180/210 gorsze → stop, restore 150)
Krzywa = live snapshot z podu H100 (raw per-step + EMA). Model na HF = checkpoint best.
eval (held-out)
psc
97.5
ppc
81
dyk
86
belebele
92
8tags
81
polemo2_in
89.5
Trenowany na train splitach KLEJ → KONTAMINACJA. Dowód: belebele +0.0 (0 przykładów w miksie) vs psc +26.5 — artefakt train-splitów, nie zdolność. NIE jest claimem leaderboardowym. Train≠test (dedup), więc to nie oszustwo, ale nieporównywalne z wynikami 5-shot leaderboardu.
2026-06-05slayer-style (ep1/2/3)CZYSTY
skład danych
styl 1004
dataset
🤗 kacperwikiel/slayer-data-v1-style ↗
1004 wyselekcjonowane przykłady stylu PL (LIMA-style: jakość > wolumen). Teacher deepseek-v4-pro, sędzia otwarty Qwen3.5. Zero danych benchmarkowych.
hiperparametry
DoRA: r16LR: ~4e-5 warmupepochs: 2steps: 60data: ~1k styl (LIMA)
krzywa loss
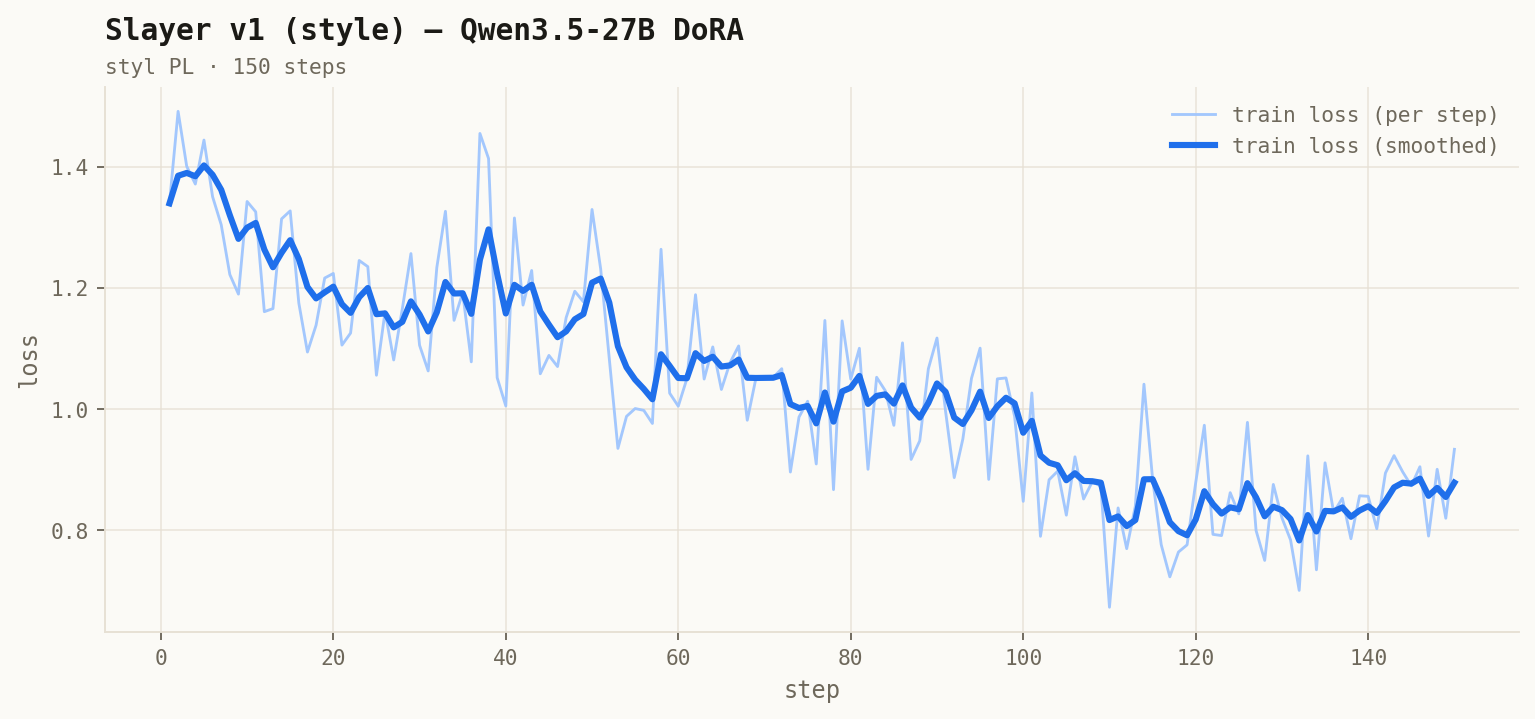
Czysty styl polski: bez nadużycia myślników, natywna fleksja, zero danych benchmarkowych. Teacher deepseek-v4-pro / sędzia otwarty Qwen3.5.
12 eksperymentów · log auto-aktualizowany przez pipeline (pipeline/run_daily.py)